OK so maybe the title goes a bit far; it might be more accurate to say "Where people are studying for the HSK" or "Where visitors to my website are from". But there's probably a pretty strong correlation between places where my site is popular, and where people are learning Chinese.
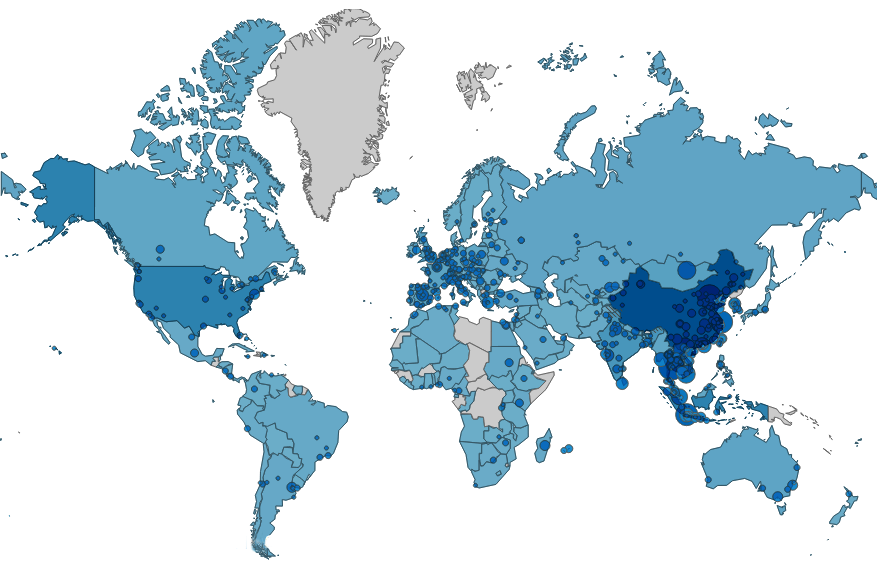
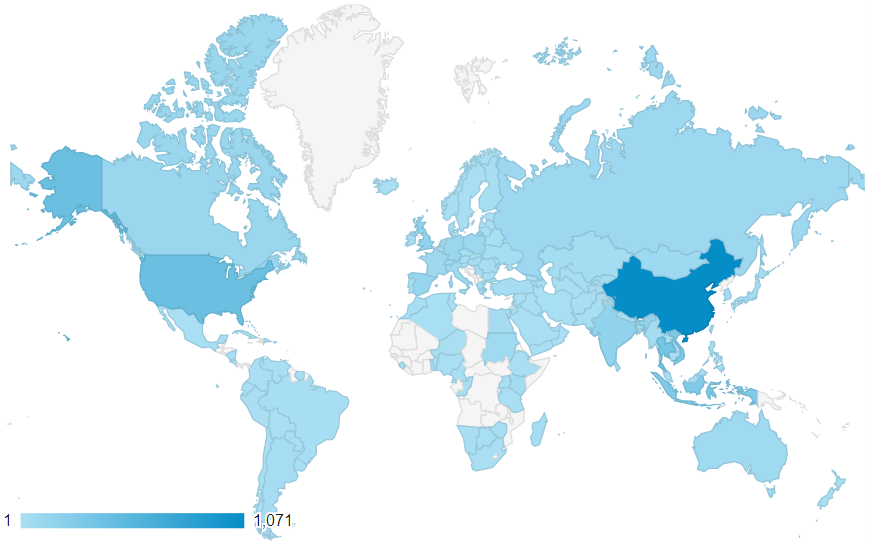
This map combines together country-level and city-level data, and it's pretty clear that most of the learners are from China (18%), Thailand (8%), and Indonesia (7%)! In Western Europe there is a fairly even spread of learners everywhere (except for a gap in central France!), without too much clustering. I wonder if this matches with more formal studies of the popularity of Chinese as a second language?
This map combines together country-level and city-level data, and it's pretty clear that most of the learners are from China (18%), Thailand (8%), and Indonesia (7%)! In Western Europe there is a fairly even spread of learners everywhere (except for a gap in central France!), without too much clustering. I wonder if this matches with more formal studies of the popularity of Chinese as a second language?
Splitting the data by 'region', shows that about 60% of the visits to my site are from Asia, 20% are from Europe, and less than 10% are from North America. There are more visits from S.E. Asia than from E. Asia (which includes China)!
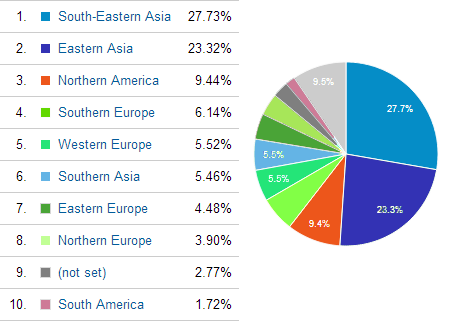
A quick summary of how Google split the regions:'
- Western Asia' is what I would call the 'Middle East',
- Central Asia is all the 'Stans,
- Southern Asia is Iran to India,
- South-East Asia is Burma and Thailand to the Philippines and Indonesia.
- East Asia is China, Mongolia, Japan, Korea.
- Northern Europe is the UK and Scandanavia.
- Western Europe is Germany and France to Switzerland.


 RSS Feed
RSS Feed